有缓冲的通道相比于无缓冲通道,多了一个缓存的功能,如下图描述的一样:
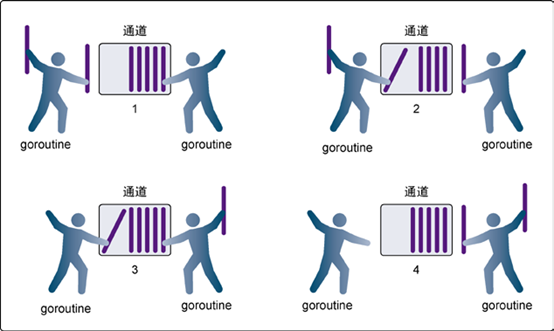
从图上可以明显看到和无缓冲通道的区别,无缓冲必须两个Goroutine都进入通道才能进行数据的交换,这个不用,如果数据有,直接就能拿走。
package ChannelDemo import ( "fmt" "math/rand" "sync" "time" ) const ( numberGoroutines = 4 taskLoad = 10 ) var bufferWg sync.WaitGroup func init() { rand.Seed(time.Now().Unix()) } func main() { //创建了一个10任务的缓冲通道 tasks := make(chan string, taskLoad) bufferWg.Add(numberGoroutines) //创建4个Goroutine for gr := 1; gr <= numberGoroutines; gr++ { go worker(tasks, gr) } //向缓冲通道中放入数据 for post := 1; post <= taskLoad; post++ { tasks <- fmt.Sprintf("Task : %d", post) } close(tasks) bufferWg.Wait() } func worker(tasks chan string, worker int) { defer bufferWg.Done() for { task, ok := <-tasks if !ok { fmt.Printf("Worker: %d : 结束工作 \n", worker) return } fmt.Printf("Worker: %d : 开始工作 %s\n", worker, task) //随机处理一下工作的时间 sleep := rand.Int63n(100) time.Sleep(time.Duration(sleep) * time.Millisecond) fmt.Printf("Worker: %d : 完成工作 %s\n", worker, task) } }
运行结果:
Worker: 3 : 开始工作 Task : 4 Worker: 2 : 开始工作 Task : 2 Worker: 1 : 开始工作 Task : 1 Worker: 4 : 开始工作 Task : 3 Worker: 4 : 完成工作 Task : 3 Worker: 4 : 开始工作 Task : 5 Worker: 2 : 完成工作 Task : 2 Worker: 2 : 开始工作 Task : 6 Worker: 3 : 完成工作 Task : 4 Worker: 3 : 开始工作 Task : 7 Worker: 1 : 完成工作 Task : 1 Worker: 1 : 开始工作 Task : 8 Worker: 3 : 完成工作 Task : 7 Worker: 3 : 开始工作 Task : 9 Worker: 1 : 完成工作 Task : 8 Worker: 1 : 开始工作 Task : 10 Worker: 4 : 完成工作 Task : 5 Worker: 4 : 结束工作 Worker: 3 : 完成工作 Task : 9 Worker: 3 : 结束工作 Worker: 2 : 完成工作 Task : 6 Worker: 2 : 结束工作 Worker: 1 : 完成工作 Task : 10 Worker: 1 : 结束工作
因为哪一个worker先从通道中取值有系统自己进行调度的,所以每次运行的结果稍微不同,但是相同的是10个任务被4个协程有条不紊的完成了
注意:main中有一句代码 Close(tasks) 关闭通道的代码非常重要。当通道关闭后,goroutine 依旧可以从通道接收数据,但是不能再向通道里发送数据。
能够从已经关闭的通道接收数据这一点非常重要,因为这允许通道关闭后依旧能取出其中缓冲的全部值,而不会有数据丢失.
五、总结
无缓冲的通道保证同时交换数据,而有缓冲的通道不做这种保证。