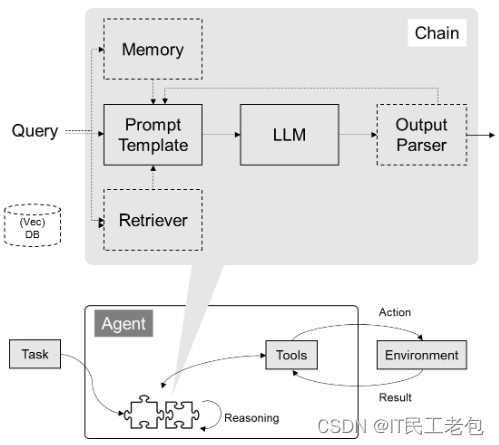
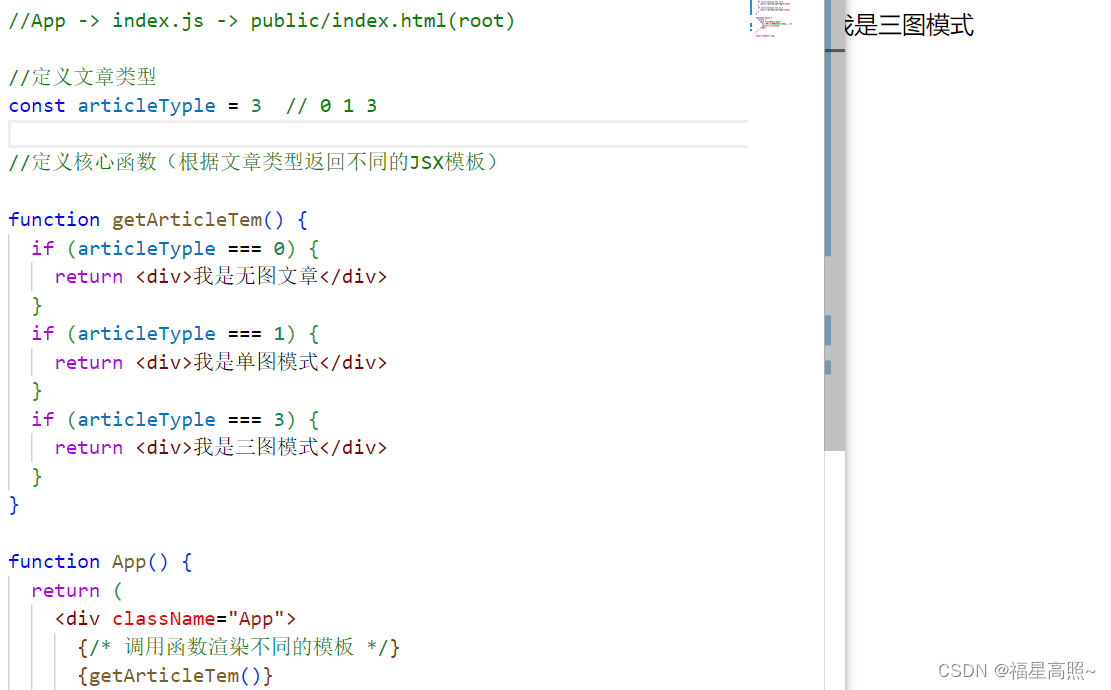
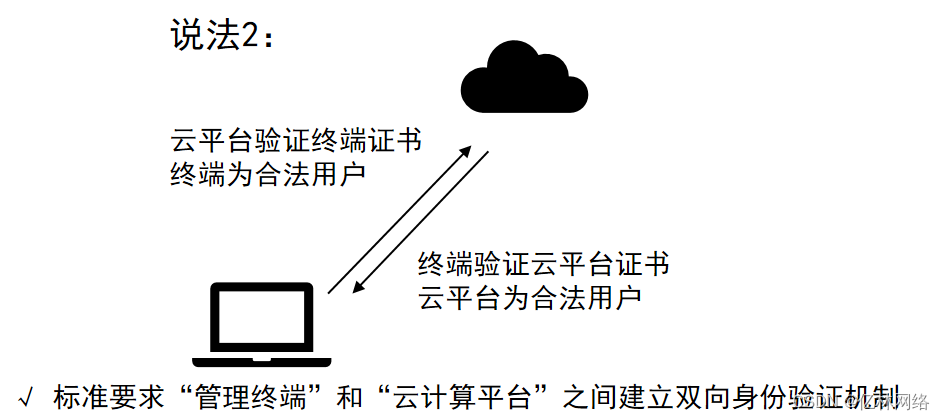
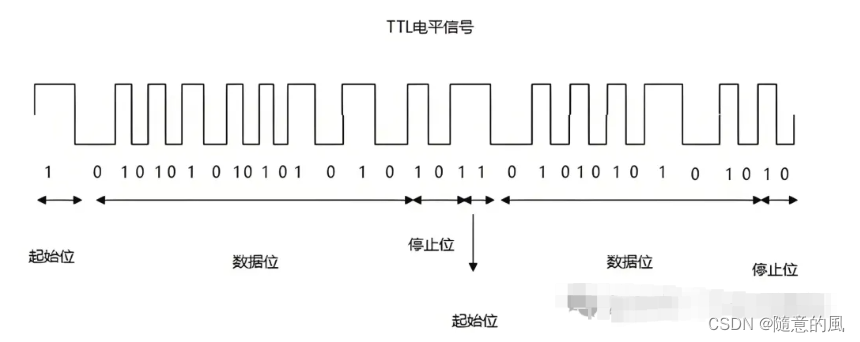
AI学习指南机器学习篇-K均值聚类(K-Means Clustering)简介
1. 引言
在机器学习领域中,无监督学习是一种常见的技术,其通过对未标记的数据进行学习,从中发现数据的模式和结构。K均值聚类(K-Means Clustering)是一种常用的无监督学习算法,被广泛应用于数据的聚类和模式发现任务中。
本篇博客将详细介绍K均值聚类的基本概念和其在无监督学习中的应用。我们将解释K均值聚类在数据聚类和模式发现中的作用和优势,并通过详细的示例来进一步说明其应用和效果。
2. K均值聚类的基本概念
K均值聚类是一种将数据分为多个类别(簇)的常用聚类算法。其基本思想是通过迭代的方式将数据划分为K个簇,使得每个数据点都属于离该数据点最近的簇的质心。K均值聚类的过程可以简述为以下几个步骤:
步骤1:初始化质心
首先需要选择K个质心作为聚类的中心点。这些质心可以是随机选择的,也可以根据数据的特点进行人工设定。
步骤2:分配数据点到质心
将每个数据点分配到离其最近的质心所属的簇。
步骤3:更新质心位置
重新计算每个簇的质心,即将质心的位置设置为该簇所有数据点的平均值。
步骤4:重复步骤2和步骤3
重复执行步骤2和步骤3,直到质心不再发生变化或者达到预定义的迭代次数。
K均值聚类的目标是最小化每个数据点与所属簇的质心之间的距离,同时最大化簇内数据点之间的相似性。
3. K均值聚类在无监督学习中的应用
K均值聚类在无监督学习中具有广泛的应用,下面我们将介绍其在数据聚类和模式发现中的作用和优势。
3.1 数据聚类
K均值聚类是一种常用的数据聚类算法,通过将数据划分为K个簇,可以将相似的数据点放在同一个簇中,从而对数据进行分组和分类。这种聚类的结果可以帮助我们理解数据的结构和模式,发现数据中隐藏的规律和信息。
举个例子,我们将使用一个简单的数据集来说明K均值聚类在数据聚类任务中的应用。假设我们有一组二维数据点,我们希望将这些数据点分成两个簇。
import numpy as np
from sklearn.cluster import KMeans
# 生成示例数据
np.random.seed(0)
X = np.concatenate([np.random.normal(loc=(0, 0), scale=0.5, size=(100, 2)),
np.random.normal(loc=(2, 2), scale=0.5, size=(100, 2))])
# 使用K均值聚类算法进行数据聚类
kmeans = KMeans(n_clusters=2)
kmeans.fit(X)
# 获取数据点所属的簇
labels = kmeans.labels_
通过上述代码,我们使用K均值聚类将数据分为两个簇,并获取每个数据点所属的簇的标签。通过可视化结果,我们可以清晰地看到数据点被正确聚类成两个簇。
3.2 模式发现
K均值聚类不仅可以用于数据聚类,还可以用于模式发现。在某些应用中,我们希望发现数据中的一些相似模式或者结构。K均值聚类可以将相似的数据点聚集在一起,从而发现这些数据中的模式。
举个例子,我们将使用一个二维数据集来说明K均值聚类在模式发现任务中的应用。假设我们有一个数据集,其中包含两种不同的模式或者结构。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
# 生成示例数据
np.random.seed(0)
X = np.concatenate([np.random.normal(loc=(-3, -3), scale=0.5, size=(100, 2)),
np.random.normal(loc=(3, 3), scale=0.5, size=(100, 2))])
# 使用K均值聚类算法进行模式发现
kmeans = KMeans(n_clusters=2)
kmeans.fit(X)
# 获取数据点所属的簇
labels = kmeans.labels_
# 可视化聚类结果
plt.scatter(X[:, 0], X[:, 1], c=labels)
plt.title("Pattern Discovery using K-Means Clustering")
plt.xlabel("X")
plt.ylabel("Y")
plt.show()
通过上述代码,我们使用K均值聚类将数据进行模式发现,并通过可视化结果展示了聚类的效果。可以观察到,K均值聚类成功地将数据分为两个不同的模式或者结构。
4. 总结
K均值聚类是一种常用的无监督学习算法,其通过迭代的方式将数据划分为K个簇,并最小化每个数据点与所属簇的质心之间的距离。K均值聚类在无监督学习中具有广泛的应用,特别适用于数据聚类和模式发现任务。通过示例,我们展示了K均值聚类在数据聚类和模式发现中的作用和优势。
希望本篇博客能够帮助读者更好地理解K均值聚类算法的基本概念和应用,为进一步学习和应用机器学习提供指导和启示。