多路复用是什么?怎么理解?
本文主要涉及为
程序中处理网络IO时的模型,对于系统内核而言网络IO模型。这里只做普及使用
IO其实就是In和Out。中文翻译是输入和输出,只要涉及到输入和输出的,我们都可以称之为IO。
例如你在磁盘中读取文件,读取文件为In,输出到其他地方为Out。
例如你Windows系统在网络通信时,读取客户端的输入数据包,这叫In,系统将数据包输出给我们编写的应用程序,这叫Out。
当然,我们如果成自身程序的角度去看网络通信的话,我们根据系统内核给予的文件描述符去获取TCP连接数据时,这就叫In,将数据输出到其他位置,这叫Out。
所以,我们可以总结,IO其实就是输入输出,它是对输入输出这个动作的统称,并不仅限于磁盘、网络等。
当然,IO相关的设备有很多,比如鼠标、触摸屏、NFC等
对于系统而言,处理IO有什么模型?
这里的系统,指的是Windows内核程序、Linux内核程序。
我们要知道,一个TCP连接到达服务器后,该连接是由系统内核程序进行管控的,它维护这条连接和上层应用与之交互的过程。
回到正题,我们今天说的是系统内核层面的IO模型情况,至于应用程序层的IO模型我会一笔带过。
同步模型
画个图更好理解:
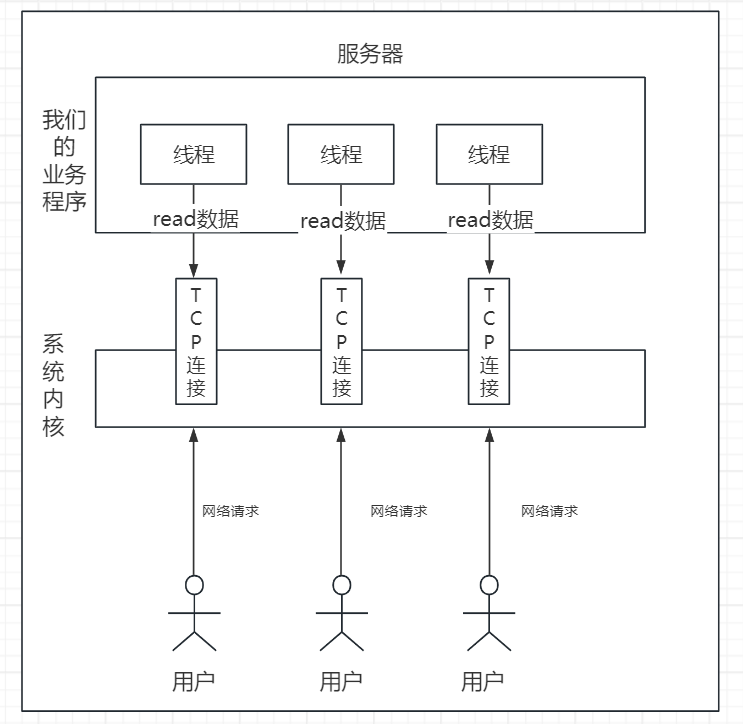
这张图中,注意我们的业务程序中线程是需要不停的读取TCP连接通道中的数据,我们可以称之为为read操作。而本质上业务程序一直不停的主动读取数据的这种情况,本质上就是一个同步模型,因为始终是应用程序主动来读取的。
此时如果我们的线程,read数据没有的话,一直等待读取到数据的这个操作,对于我们业务程序而言,就是阻塞模型。而业务程序如果读取read后发现没有数据,直接跳过,这个就是非阻塞模型。至于业务程序读取到数据后,自身如何去操作,其实就是业务层面的同步和异步模型。
说到这里,你应该也明白了,系统内核层面的IO模型和我们业务程序层面的IO模型是可以完全不相关的。举个例子,我们先不谈系统内核层面,只说应用程序,应用程序读取到数据后,读取数据的线程用来处理业务,那就是同步模型;而应用程序读取数据的线程不参与业务处理,只处理网络连接的事情,当其他业务处理线程执行完业务逻辑后再让处理连接的线程响应数据,这就是异步模型。
那么此时你会有疑问,每次都要应用程序主动去读取,这太浪费资源了,应用程序能不能等数据来,而不是主动去找内核要,那么就代表着系统内核级别上有没有异步模型的存在?
实际上是有的,我们马上来描述。
异步模型
我们可以假想一下它的模型:
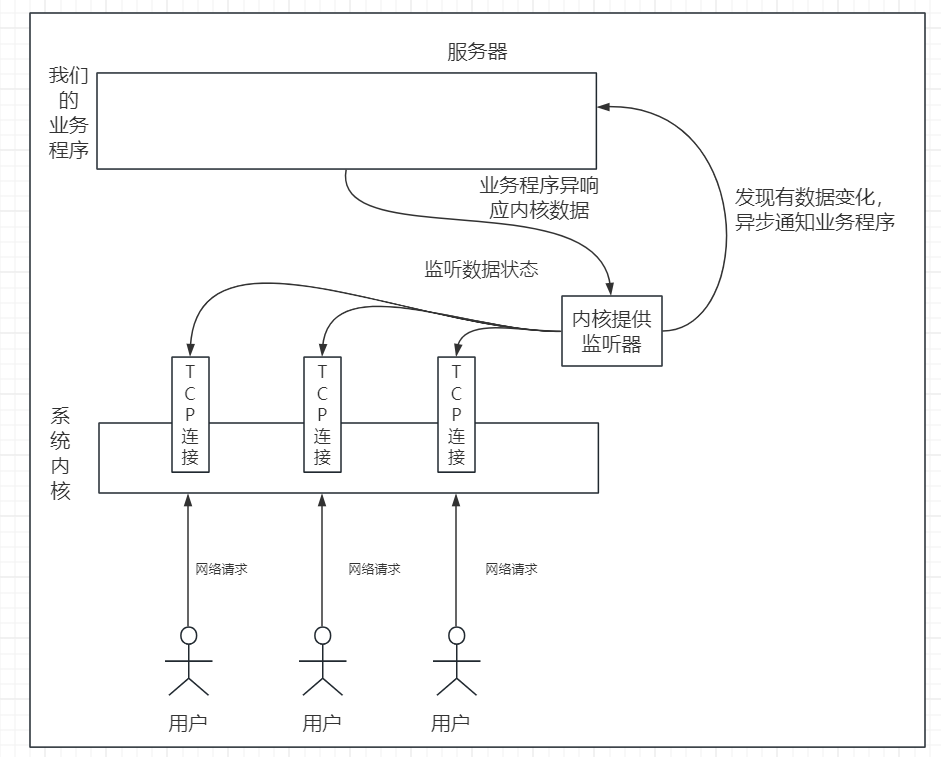
其实真实的内核异步网络IO的比这个图大很多,这里为了方便理解,做了一些简化。
从这张图我们可以知道,内核要实现异步的网络IO本身是可以实现的,但要注意,其实内核的异步IO应用并不广泛,原因如下:
1、内核实现难度增大,出问题的风险更大:内核要实现异步IO要比同步复杂得多,涉及到回调函数、事件循环等概念,要知道内核程序对稳定性要求极高,因为它是整个程序运行最基础的部分,增加复杂度则意味着增加风险。
2、性能考虑:虽然异步IO理论上可以提高性能,但在某些情况下,它可能不会带来显著的性能提升,尤其是当系统已经通过其他方式(如多线程或多路复用)进行了优化时。
3、内核实现限制:在Linux系统中,真正的异步IO模型发展面临一些挑战,特别是内核实现上的限制和历史遗留问题。例如,Linux的io_uring虽然是真在往异步IO发展,但在某些领域(如网络IO)还是基于epoll这种IO多路复用机制更加稳定和成熟。
等等还有很多理由可以说,总体来说,内核的异步IO应用不广泛主要是在于复杂度与稳定性上,但还有一个重要因素,也就是IO多路复用模型的实现。
IO多路复用模型
前面铺垫那么多,就是为了引出IO多路复用模型。
我们前面说了异步IO模型的本质是为了提高性能,而在内核层面上为了提高这个性能付出的代价未免太大了一点,那么就需要产生一个折中的办法。
这个折中的办法需要满足以下条件:
1、应用程序不能一直去等待读取数据,节约线程资源。
2、内核方面不能用异步操作,保持原来同步读的模型。
那么**【多路复用】**就能满足这两个条件,多路复用模型如图所示:
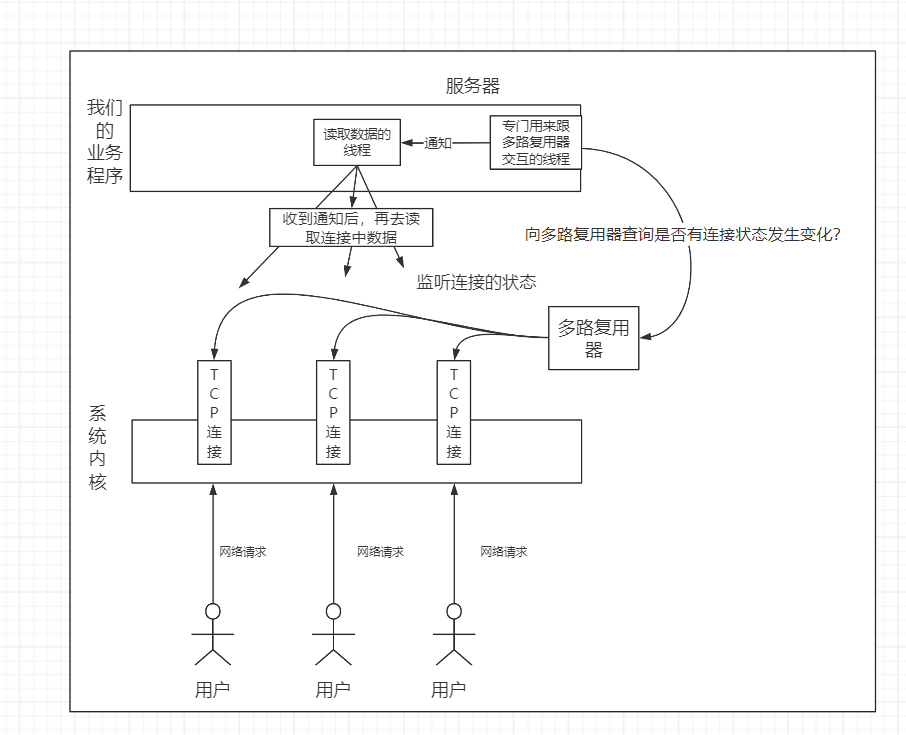
内核提供多路复用器,多路复用器中会监听各个网络TCP连接的状态,然后业务程序方面有专门的线程用来不停往多路复用器处查询连接状态,当发现有连接的状态发生变更后,就通知其他对应的线程去读取数据。
这样就达到了我们前面说的两个条件,应用程序无需一直反复尝试读取连接中的数据,而内核也无需实现异步模型。
在目前的环境下,绝大多数系统和应用都是使用这类模型来处理网络请求,例如Windows的IOCP,Linux的epoll,而业务程序方面代表性最强的则是Netty。
当然,多路复用可不是这一点讲清楚的,这里让大家对多路复用的基本原理有个了解,其实在上图中每一个涉及的点都有不同的实现方式,可以自行网上搜索了解下。
那么最后做个总结:
1、业务程序自身处理IO和内核处理IO是无关的,本身是两个层面。
2、内核层面绝大多数都是同步模型,此时加入多路复用后性能已经足够当下环境的需求,而异步模型由于复杂度和稳定性问题普及并不广泛。
3、多路复用器不仅仅用于IO方面,其他很多场景都可以使用,所以多路复用器我们要理解其模型,而不能限定于IO。
4、在Java层面,多路复用器在JVM的NIO包中已经实现好了,我们只管用就行,而当我们使用了Netty这类集成框架后,大多数情况下我们并不需要关系底层的内容